import jax
from jax import random, Array
import jax.numpy as jnp
import matplotlib.pyplot as plt
import seaborn as sns
from typing import *
from gp import k, covariance_solve, flatten, PlotContext, cholesky_inv
key = random.PRNGKey(42) # Create a random key
Gaussian Process Regression with Derivatives (GPwDs)#
In this notebook, we will explore Gaussian Process Regression with Derivatives (GPwDs) which can be applied to solve function approximation where we have the additional information of the derivatives of the function evaluated at inputs.
As a reminder, GP regression can be applied to solve function approximation, i.e., learning an unknown function \(f: \mathbb{R}^D \rightarrow \mathbb{R}\) from a dataset \(\mathcal{D} = \{(x_i, y_i) | x_i \in \mathbb{R}^D, y_i \in \mathbb{R} \}_i\) of function inputs and outputs.
Function Approximation with Derivative Information#
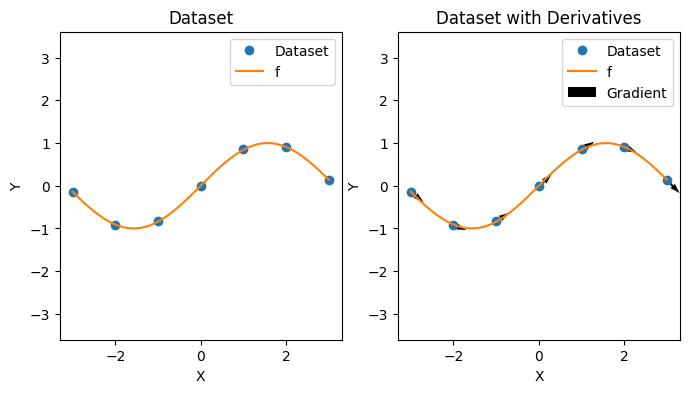
As a reminder, in function approximation, we attempt to learn an unknown function \(f: \mathbb{R}^D \rightarrow \mathbb{R}\) from some hypothesis class \(\mathcal{H}\) given a dataset \(\mathcal{D} = \{(x_i, y_i) | x_i \in \mathbb{R}^D, y_i \in \mathbb{R} \}_{1 \leq i \leq N}\) of function input and output pairs \((x_i, y_i)\). In the setting with derivative information, we have a dataset \(\mathcal{D} = \{(x_i, y_i, g_i) | x_i \in \mathbb{R}^D, y_i \in \mathbb{R}, g_i \in \mathbb{R}^D \}_i\) where \(g_i = \nabla_{x_i} y_i\) is the gradient of \(y_i\) with respect to \(x_i\). We give an example of a dataset below.
def create_toy_deriv_dataset(f: Callable, key):
N = 7; D = 1
xs = jnp.linspace(-3, 3, N).reshape(-1, 1)
# 1a. Sample random function
def f(x: Array) -> float:
return jnp.sin(x)
# 1b. Associated gradient
grad_f = jax.jacrev(f)
# 2. Sample noise
Sigma = jnp.diag(jnp.array([1e-4, 1e-2]))
es = random.multivariate_normal(key, mean=jnp.zeros(1 + D), cov=Sigma, shape=(N,))
# 3. Produce observations
ys = jnp.array([f(x) + e[0] for x, e in zip(xs, es)]) # outputs
gs = jnp.array([grad_f(x).reshape(-1) + e[1] for x, e in zip(xs, es)])
return xs, ys, gs, Sigma
f = lambda x: jnp.sin(x)
xs, ys, gs, Sigma = create_toy_deriv_dataset(f, key)
D = xs[0].shape[0]
# Plot
def plot_deriv_dataset(xs: Array, ys: Array, gs: Array, f: Callable) -> None:
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1); plt.axis("equal")
plt.plot(xs, ys, marker="o", linestyle="None", label="Dataset")
plt.plot(jnp.linspace(-3, 3), f(jnp.linspace(-3, 3)), label="f")
plt.title("Dataset"); plt.xlabel("X"); plt.ylabel("Y"); plt.legend();
plt.subplot(1, 2, 2); plt.axis("equal")
origin = jnp.array([xs, ys])
plt.plot(xs, ys, marker="o", linestyle="None", label="Dataset")
plt.plot(jnp.linspace(-3, 3), f(jnp.linspace(-3, 3)), label="f")
plt.quiver(*origin, jnp.ones(len(xs)), gs, label="Gradient")
plt.title("Dataset with Derivatives"); plt.xlabel("X"); plt.ylabel("Y"); plt.legend();
plot_deriv_dataset(xs, ys, gs, f)
Gaussian Process with Derivatives (GPwD) Model#
A GP has the property that if
then
We can use this observation to construct a Gaussian Process with Derivatives (GPwD) model. The notation \(GP(\tilde{\mu}, \tilde{k})\) indicates a GPwD model with mean function \(\tilde{\mu}: \mathbb{R}^D \rightarrow \mathbb{R}^{1 + D}\) and kernel function \(k: \mathbb{R}^D \times \mathbb{R}^D \rightarrow \mathbb{R}^{(1 + D) \times (1 + D)}\).
Define a class of functions that packs together a function and its gradient as in
Then
whenever \(f \sim GP(\mu, k)\) and \(\nabla f \sim GP(\nabla \mu, \nabla k \nabla^T)\).
Mean#
The mean function \(\tilde{\mu}: \mathbb{R}^D \rightarrow \mathbb{R}^{1 + D}\) is defined in terms of a base mean function \(\mu: \mathbb{R}^D \rightarrow \mathbb{R}\) as
As before, without loss of generality, we will use a mean function \(\mu = 0\).
Kernel#
The kernel function \(k: \mathbb{R}^D \times \mathbb{R}^D \rightarrow \mathbb{R}^{(1 + D) \times (1 + D)}\) is defined in terms of a based kernel function \(k: \mathbb{R} \times \mathbb{R} \rightarrow \mathbb{R}\) as
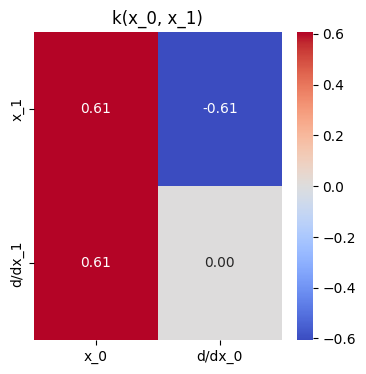
def kern_blk(k: Callable, x1: Array, x2: Array) -> Array:
kern = jnp.array([k(x1, x2)])
jac2 = jax.jacrev(k, argnums=1)(x1, x2)
f_jac1 = jax.jacrev(k, argnums=0)
jac1 = f_jac1(x1, x2).reshape(-1, 1)
# Using forward-mode AD with reverse-mode AD to get the second derivative
hes = jax.jacfwd(f_jac1, argnums=1)(x1, x2)
# Put everything together
top = jnp.concatenate([kern, jac2]).reshape(1, -1)
bot = jnp.concatenate([jac1, hes], axis=1)
K = jnp.concatenate([top, bot])
return K
plt.figure(figsize=(4, 4))
sns.heatmap(
kern_blk(k, xs[0], xs[1]), annot=True, cmap='coolwarm', fmt='.2f',
xticklabels=["x_0", "d/dx_0"], yticklabels=["x_1", "d/dx_1"]
)
plt.title("k(x_0, x_1)");
Covariance Matrix#
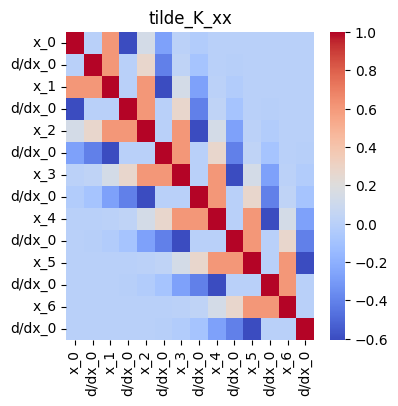
Define a covariance matrix
which uses the GPwD kernel function \(\tilde{k}\).
def mk_cov_blk(k: Callable, xs1: Array, xs2: Array) -> Array:
return jnp.concatenate([
jnp.concatenate([
kern_blk(k, x1, x2) for x2 in xs2
], axis=1) for x1 in xs1
])
tilde_K_xx = mk_cov_blk(k, xs, xs)
plt.figure(figsize=(4, 4))
sns.heatmap(
tilde_K_xx, annot=False, cmap='coolwarm', fmt='.2f',
xticklabels=flatten([[f"x_{i}"] + [f"d/dx_{d}" for d in range(D)] for i in range(len(xs))]),
yticklabels=flatten([[f"x_{i}"] + [f"d/dx_{d}" for d in range(D)] for i in range(len(xs))])
)
plt.title("tilde_K_xx");
Gaussian Finite Dimensional Distributions#
Since a GPwD is a multi-variate GP, we also have Gaussian finite dimensional distributions as in
for any finite set of inputs \(\{x_1, \dots, x_N \}\). This relates the functions that a GPwD is defining via \(\tilde{\mu}\) and \(\tilde{k}\) with the dataset.
The variable \(\tilde{\mu}_x\) is the vector of mean values
The variable \(\tilde{K}_{xx}\) is the covariance matrix from before.
For simplicity of notation, we may drop the subscripts related to the datasets so we may simply write \(\tilde{\mu}\) for the vector of means and \(\tilde{K}\) for the covariance matrix.
GPwD Regression#
We perform GPwD regression with the dataset \(\mathcal{D} = \{(x_i, y_i, g_i) \}_{1 \leq i \leq N}\) by computing a posterior predictive distribution.
Generative Process#
We peform GPwD regression using the generative process below
Posterior Predictive Distribution#
Define a joint distribution on latent variables \(\tilde{f} = (\tilde{f}(x_1) \, \dots \, \tilde{f}(x_N))^T\) (i.e., evaluated at \(\{x_1, \dots, x_N\}\)) and a test \(\tilde{f}_* = \tilde{f}(x_*)\) (i.e., evaluated at \(x_*\)).
Then the posterior predictive distribution is
following the vanilla GP posterior predictive prediction. The computational complexity of solving for a GPwD model with \(N\) points in \(D\) dimensions is \(O(N^3D^3)\).
def fit_gpwd(k: Callable, xs: Array, hs: Array, Sigma) -> Array:
tilde_K_xx_noise = jnp.concatenate([
jnp.concatenate([
kern_blk(k, x1, x2) + Sigma for x2 in xs
], axis=1) for x1 in xs
])
return covariance_solve(tilde_K_xx_noise, hs), tilde_K_xx_noise
hs = jnp.concatenate([jnp.concatenate([y, g]) for y, g in zip(ys, gs)])
alpha_beta, tilde_K_xx_noise = fit_gpwd(k, xs, hs, Sigma)
alpha_beta
Array([ 46.33195 , 17.5432 , 60.18659 , 82.009705 ,
-50.762745 , 93.34205 , -118.7323 , -3.2561462,
-38.896416 , -91.386826 , 56.32993 , -77.16064 ,
44.082905 , -18.354553 ], dtype=float32)
def gpwd_post_pred_mean(k: Callable, xs: Array, alpha_beta: Array, x_star: Array) -> Array:
"""Posterior predictive mean.
"""
K_star_f = jnp.concatenate([kern_blk(k, x_star, x) for x in xs], axis=1)
return K_star_f @ alpha_beta
def gpwd_post_pred_cov(k: Callable, xs: Array, tilde_K_xx_noise: Array, x_star: Array) -> Array:
"""Posterior predictive covariance.
"""
K_star_star = kern_blk(k, x_star, x_star)
K_star_f = jnp.concatenate([kern_blk(k, x_star, x) for x in xs], axis=1)
return K_star_star - K_star_f @ cholesky_inv(tilde_K_xx_noise) @ K_star_f.transpose()
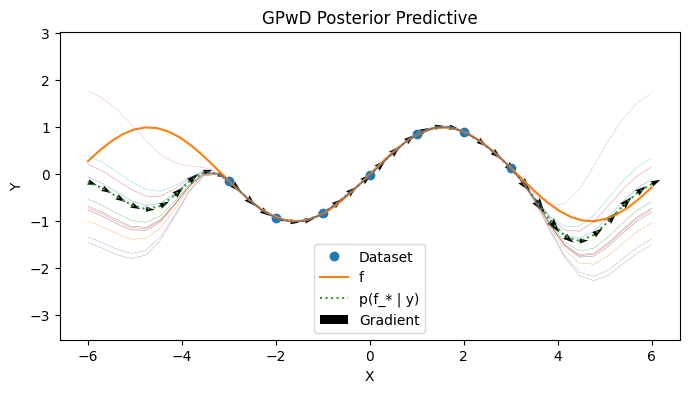
Visualizing the Posterior Predictive#
We visualize the GPwD model below. Observe that the shape of the uncertainty has been altered by the presence of gradient information compared to the vanilla GP case.
# Create posterior prediction
test_xs = jnp.linspace(-6, 6, 40)
post_tfs = [gpwd_post_pred_mean(k, xs, alpha_beta, jnp.array([x])) for x in test_xs]
post_mean = [h[0] for h in post_tfs]
post_cov = [gpwd_post_pred_cov(k, xs, tilde_K_xx_noise, jnp.array([x])) for x in test_xs]
post_ys = [random.normal(key, shape=(12,)) * jnp.sqrt(post_cov[i][0][0]) + post_mean[i] for i in range(len(test_xs))]
post_gs = [h[1:] for h in post_tfs]
with PlotContext(title="GPwD Posterior Predictive", xlabel="X", ylabel="Y") as ax:
# Plot dataset
plt.plot(xs, ys, marker="o", linestyle="None", label="Dataset")
plt.plot(jnp.linspace(-6, 6), f(jnp.linspace(-6, 6)), label="f")
# Plot predictions
plt.plot(test_xs, post_mean, label="p(f_* | y)", linestyle="dotted")
origin = jnp.array([test_xs, post_mean])
plt.quiver(*origin, jnp.ones(len(test_xs)), post_gs, label="Gradient", width=0.01, scale=70)
plt.plot(test_xs, post_ys, linewidth=0.2)
References#
Appendix#
Appendix: Kernel Derivation#
We need to compute the covariances \(Cov(f(x), \nabla f(x))\) and \(Cov(\nabla f(x), \nabla_x f(x))\).
Appendix: Gradient of Prediction and Prediction of Gradient#
The gradient of the prediction of the function value and the prediction of the gradient value of the function in a GPwD is the same.
Thus